Update: The problem is now fixed in Pytorch but can still happen in tensorflow-keras. Discussion on reddit.
Bugs in ML code are notoriously hard to fix - they don’t cause compile errors but silently regress accuracy. Once you have endured the pain and fixed one of these, the lesson is forever etched into your brain, right? Wrong. Recently, an old foe made a comeback - a familiar bug bit me again! As before, the performance improved significantly after fixing it.
The bug was subtle and easy to make. How many others has it done damage to? Curious, I downloaded over a hundred thousand repositories from GitHub that import PyTorch, and analysed their source code. I kept projects that define a custom dataset, use NumPy’s random number generator with multi-process data loading, and are more-or-less straightforward to analyse using abstract syntax trees. Out of these, over 95% of the repositories are plagued by this problem. It’s inside PyTorch’s official tutorial, OpenAI’s code, and NVIDIA’s projects. Even Karpathy admitted falling prey to it.
The bug
The canonical way to load, pre-process and augment data in PyTorch is to subclass the torch.utils.data.Dataset and overwrite its __getitem__ method. To apply augmentations, such as random cropping and image flipping, the __getitem__ method often makes use of NumPy to generate random numbers. The map-styled dataset is then passed to the DataLoader to create batches. The training pipeline might be bottlenecked by data pre-processing, and therefore it makes sense to load data in parallel. This can be achieved by increasing the num_workers parameter in the DataLoader object.
The problem: this workflow results in identical augmentations.
A minimal example
To make the issue concrete, here’s an example dataset which returns three-element random vectors. We use a batch size of two and four worker processes.
import numpy as np
from torch.utils.data import Dataset, DataLoader
class RandomDataset(Dataset):
def __getitem__(self, index):
return np.random.randint(0, 1000, 3)
def __len__(self):
return 16
dataset = RandomDataset()
dataloader = DataLoader(dataset, batch_size=2, num_workers=4)
for batch in dataloader:
print(batch)
The code returns the following tensors:
tensor([[116, 760, 679], # 1st batch, returned by process 0
[754, 897, 764]])
tensor([[116, 760, 679], # 2nd batch, returned by process 1
[754, 897, 764]])
tensor([[116, 760, 679], # 3rd batch, returned by process 2
[754, 897, 764]])
tensor([[116, 760, 679], # 4th batch, returned by process 3
[754, 897, 764]])
tensor([[866, 919, 441], # 5th batch, returned by process 0
[ 20, 727, 680]])
tensor([[866, 919, 441], # 6th batch, returned by process 1
[ 20, 727, 680]])
tensor([[866, 919, 441], # 7th batch, returned by process 2
[ 20, 727, 680]])
tensor([[866, 919, 441], # 8th batch, returned by process 3
[ 20, 727, 680]])
The random numbers returned from each process are identical!
Why does this happen?
PyTorch uses multiprocessing to load data in parallel. The worker processes are created using the fork start method. This means each worker process inherits all resources of the parent, including the state of NumPy’s random number generator.
The fix
The DataLoader constructor has an optional worker_init_fn parameter. This function is called in each worker process at initialization before any data loading has happened. You can set the seed for NumPy in the worker_init_fn, for example:
def worker_init_fn(worker_id):
np.random.seed(np.random.get_state()[1][0] + worker_id)
dataset = RandomDataset()
dataloader = DataLoader(dataset, batch_size=2, num_workers=4,
worker_init_fn=worker_init_fn)
for batch in dataloader:
print(batch)
The code outputs different values for each batch, as one would expect:
tensor([[282, 4, 785],
[ 35, 581, 521]])
tensor([[684, 17, 95],
[774, 794, 420]])
tensor([[939, 988, 37],
[983, 933, 821]])
tensor([[832, 50, 453],
[ 37, 322, 981]])
tensor([[180, 413, 50],
[894, 318, 729]])
tensor([[530, 594, 116],
[636, 468, 264]])
tensor([[142, 88, 429],
[407, 499, 422]])
tensor([[ 69, 965, 760],
[360, 872, 22]])
But wait a minute, when we iterate over epochs,
for epoch in range(3):
print(f"epoch: {epoch}")
for batch in dataloader:
print(batch)
print("-"*25)
this happens:
epoch: 0
tensor([[282, 4, 785],
[ 35, 581, 521]])
tensor([[684, 17, 95],
[774, 794, 420]])
tensor([[939, 988, 37],
[983, 933, 821]])
tensor([[832, 50, 453],
[ 37, 322, 981]])
-------------------------
epoch: 1
tensor([[282, 4, 785],
[ 35, 581, 521]])
tensor([[684, 17, 95],
[774, 794, 420]])
tensor([[939, 988, 37],
[983, 933, 821]])
tensor([[832, 50, 453],
[ 37, 322, 981]])
-------------------------
epoch: 2
tensor([[282, 4, 785],
[ 35, 581, 521]])
tensor([[684, 17, 95],
[774, 794, 420]])
tensor([[939, 988, 37],
[983, 933, 821]])
tensor([[832, 50, 453],
[ 37, 322, 981]])
-------------------------
(the dataset length is reduced from 16 to 8 for brevity).
Iterating over the dataset three times produces the same random numbers at each epoch. This happens because all changes to random states are local to each worker. By default, the worker processes are killed at the end of each epoch, and all worker resources are lost. At the same time, the random state in the main process hasn’t changed, and it’s used to initialize each worker process again.
Therefore you need to change the NumPy’s seed at every epoch, for example by np.random.seed(initial_seed + epoch).
Moreover, you won’t have these issues if you sample random numbers using PyTorch (for example, torch.randint) or Python’s built-in random number generator. PyTorch takes care of these by setting the above seeds to seed + worker_id automatically.
In the wild examples
Here I have listed a few projects with the aforementioned bug.
Official PyTorch tutorial on custom datasets
A go-to tutorial for using a custom dataset in PyTorch is the one listed on their website. The tutorial demonstrates how to use the Dataset and DataLoader classes on a face-landmarks dataset. It also mentions the importance of data augmentation, and provides an example of a random crop augmentation. This is implemented using NumPy’s random number generator.
top = np.random.randint(0, h - new_h)
left = np.random.randint(0, w - new_w)
Following the tip of speeding up data loading by increasing num_workers, you get identical crops:

(batch size 8, num_workers 2, random crop augmentation)
OpenAI’s EBM
In the paper Implicit Generation and Modeling with Energy-Based Models, an energy-based model is used for generative modeling of images. The dataset’s __getitem__ method reads images and labels from disk, corrupts the former, and returns all three:
if FLAGS.datasource == 'default':
im_corrupt = im + 0.3 * np.random.randn(image_size, image_size)
elif FLAGS.datasource == 'random':
im_corrupt = 0.5 + 0.5 * np.random.randn(image_size, image_size)
return im_corrupt, im, label
These corruptions, however, are identical:
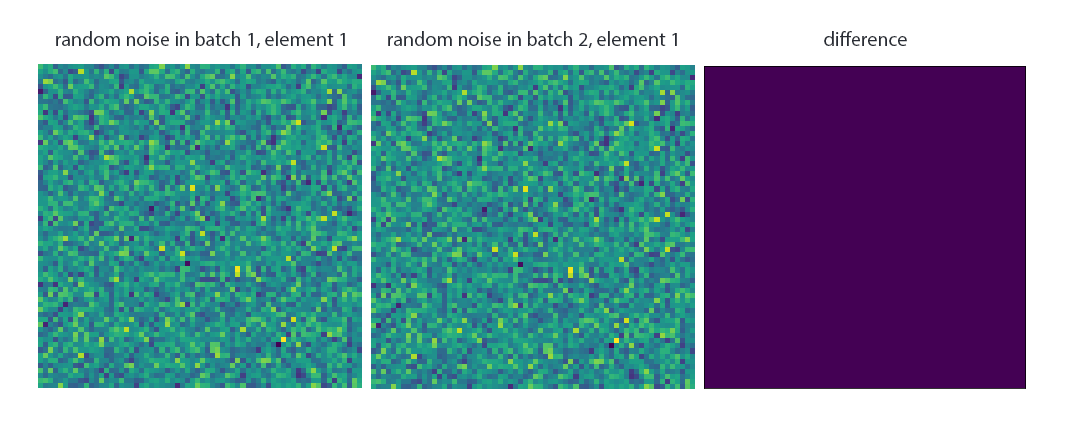
(the first corrupted image in batch 1 and 2)
MelGAN
The official code for MelGAN, a model for generative audio synthesis published in the NeurIPS conference, augments the loudness of audio files by sampling random scalars using NumPy.
data, sampling_rate = load(full_path, sr=self.sampling_rate)
data = 0.95 * normalize(data)
if self.augment:
amplitude = np.random.uniform(low=0.3, high=1.0)
data = data * amplitude
With num_workers set to four, the audio levels are identical between the processes.
Conclusion
The bug is easy to make. In some cases, it has minimal effect on final performance. In others, the identical augmentations can cause severe degradations.
Based on the analysis of open-source PyTorch projects, I am afraid the issue is present in many codebases supporting real products. I hope that better awareness of the trap, and eventually, better handling of it in PyTorch, makes these products a little bit better.
Thanks to Sten Sootla and Kaspar Märtens for their comments and suggestions.
Updates:
-
The problem is now fixed in Pytorch: relevant pull request.
-
The post generated a lively discussion on reddit. It was one of the most discussed and upvoted posts for the month.
-
The same problem happens in
tensorflow-keraswhen using theSequenceclass. It’s way more hidden and harder to fix.
import numpy as np
import tensorflow as tf
class RandomDataset(tf.keras.utils.Sequence):
def __getitem__(self, ix):
x = np.random.randint(0, 1000, 3)
x = np.array(x, dtype=np.float32)
y = np.array([1]*3, dtype=np.float32)
print(f"{ix}: {x}")
return x, y
def __len__(self):
return 16
def create_identity_model():
model = tf.keras.Sequential()
model.add(tf.keras.layers.Layer())
return model
model = create_identity_model()
model.compile(optimizer="adam", loss="mse")
dataset = RandomDataset()
model.fit(
dataset,
steps_per_epoch=16,
epochs=1,
verbose=0,
workers=4,
use_multiprocessing=True,
shuffle=False)
The above code outputs the following:
3: [631. 448. 701.]
1: [631. 448. 701.]
0: [631. 448. 701.]
2: [631. 448. 701.]
4: [972. 209. 426.]
6: [972. 209. 426.]
7: [478. 428. 715.]
5: [972. 209. 426.]
9: [478. 428. 715.]
8: [972. 209. 426.]
10: [624. 644. 844.]
11: [478. 428. 715.]
12: [624. 644. 844.]
13: [478. 428. 715.]
14: [471. 538. 33.]
15: [624. 644. 844.]